the bower model¶
male satin bowerbirds spend weeks building and decorating a bower, a small twin-walled archway of twigs, and then arrange a careful collection of blue trinkets at its entrance. they curate. they rearrange. they have favorites. they remove things that don't fit. they replace dry leaves with fresh ones.
this is the closest thing in nature to what we want an agent's memory to do, and it's the design metaphor bowerbird is built around.
the three motions¶
gather¶
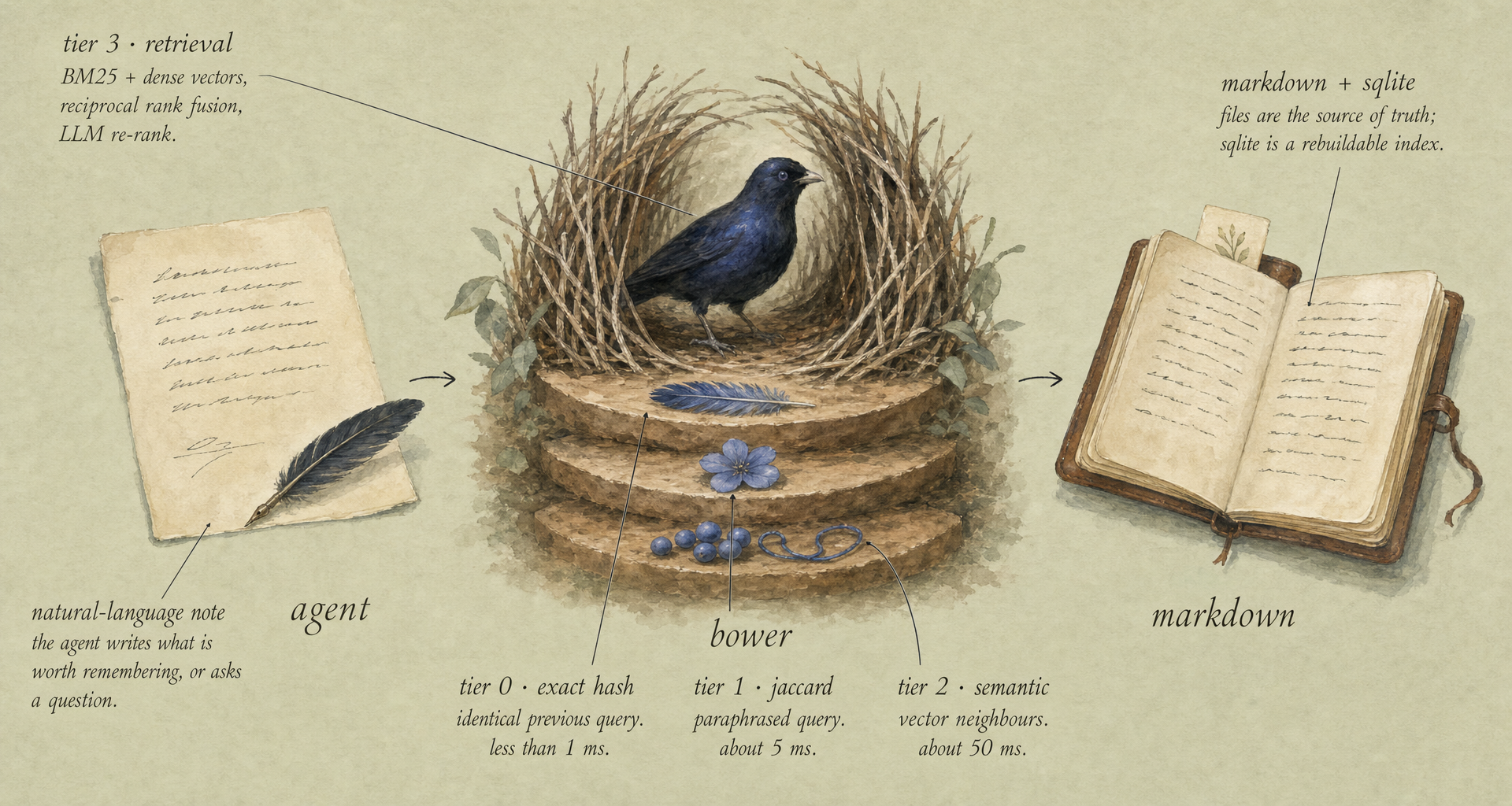
bower curate is the gather motion. when something is worth remembering, the agent calls it.
the input is a natural-language note. behind the scenes:
- an LLM extracts the underlying facts, patterns, decisions, and procedures into structured JSON.
- each piece is embedded by
gemini-embedding-001(or ONNX locally), then deduped against the existing corpus by cosine similarity. - surviving new pieces are written as markdown files under
~/.bowerbird/tree/<category>/with YAML frontmatter holding the metadata. - the sqlite cache picks them up.
the filesystem is the source of truth. sqlite is a rebuildable cache.
arrange¶
bower dream is the arrange motion. periodically, or when triggered by idle, the system runs offline analysis:
- link discovery finds typed edges between memories (
related_to,contradicts,supersedes). - deduplication merges near-duplicates by cosine threshold.
- promotion moves frequently-accessed memories up through maturity tiers:
draft→validated→core. unused ones decay towardarchived. - synthesis generates summary "patterns" from clusters of related facts.
low-confidence changes drop into a pending_review table for human approval. high-confidence ones auto-apply.
retrieve¶
bower query is the retrieve motion. queries pass through four cascading tiers:
| Tier | What | When | Latency |
|---|---|---|---|
| 0 | exact-hash cache | identical previous query | < 1 ms |
| 1 | jaccard paraphrase cache | trivially-rephrased query | ~ 5 ms |
| 2 | semantic cosine cache | "asked something similar" | ~ 50 ms |
| 3 | BM25 + vector + RRF + LLM re-rank | fresh query | ~ 500 ms - 1 s |
cheaper tiers run first; the system only pays for Tier 3 when the cheap ones miss.
the tree on disk¶
~/.bowerbird/
├── tree/
│ ├── architecture/
│ │ ├── auth/
│ │ │ ├── jwt-token-expiry-a3f1.md
│ │ │ └── oauth-callback-flow-7c2e.md
│ │ └── database/
│ │ └── postgres-replication-9c7d.md
│ ├── decisions/
│ │ ├── pinned-go-version-23-2b8e.md
│ │ └── moved-off-lambda-fargate-c4a1.md
│ └── procedures/
│ └── deploy-cluster-via-flux-d8f2.md
├── index.db # sqlite cache (rebuildable)
└── snapshots/ # dream rollback points
each .md file looks like:
---
id: jwt-token-expiry-a3f1
type: decision
maturity: validated
created: 2026-05-12T11:24:33Z
updated: 2026-06-01T09:01:02Z
importance: 0.74
access_count: 14
embedding_hash: bf0e...
relations:
- { type: related_to, target: oauth-callback-flow-7c2e }
---
# JWT token expiry
We use JWT tokens with 24-hour expiry for API authentication. The decision
was made for the v2 API rollout in May 2026. Refresh tokens are 30 days.
you can edit, move, or delete these files at will. bower reindex rebuilds the sqlite cache from the tree if you want to force it; otherwise reconciliation happens lazily on the next query.
why filesystem-first¶
most other agent memory systems treat the database as the source of truth, with optional markdown export. that makes them brittle:
- if the database corrupts, you've lost everything
- you can't
git diffto see what your agent learned this week - you can't
vima memory to fix a typo - you can't
mva memory to reorganize your tree - you can't
syncthingyour memory across machines
bowerbird inverts it. the filesystem is the source of truth. sqlite is a derived index, like a .git/index file. delete it and the world keeps spinning.